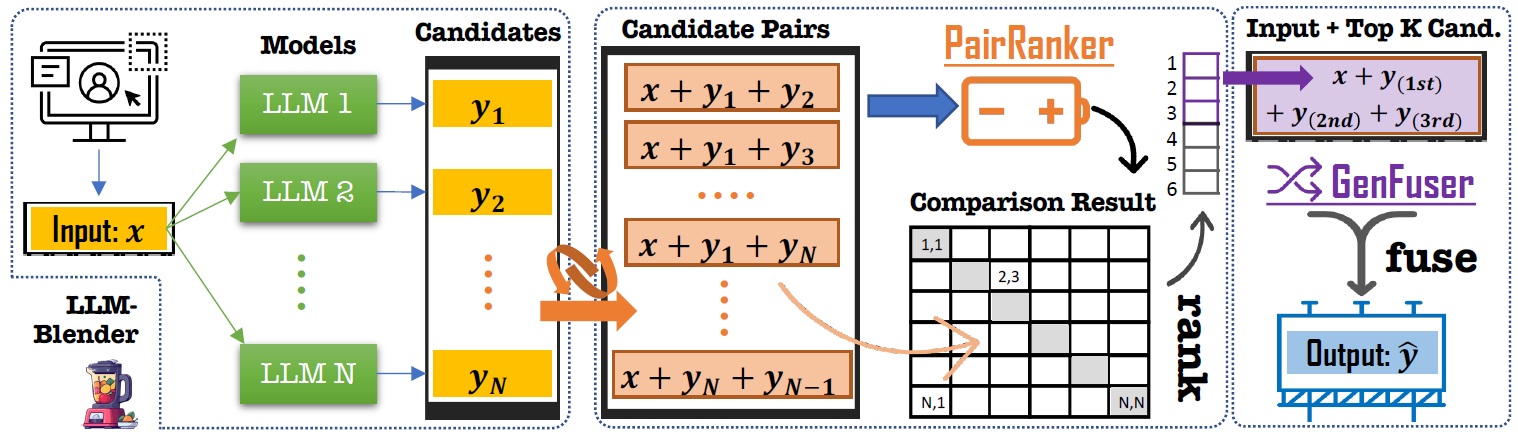
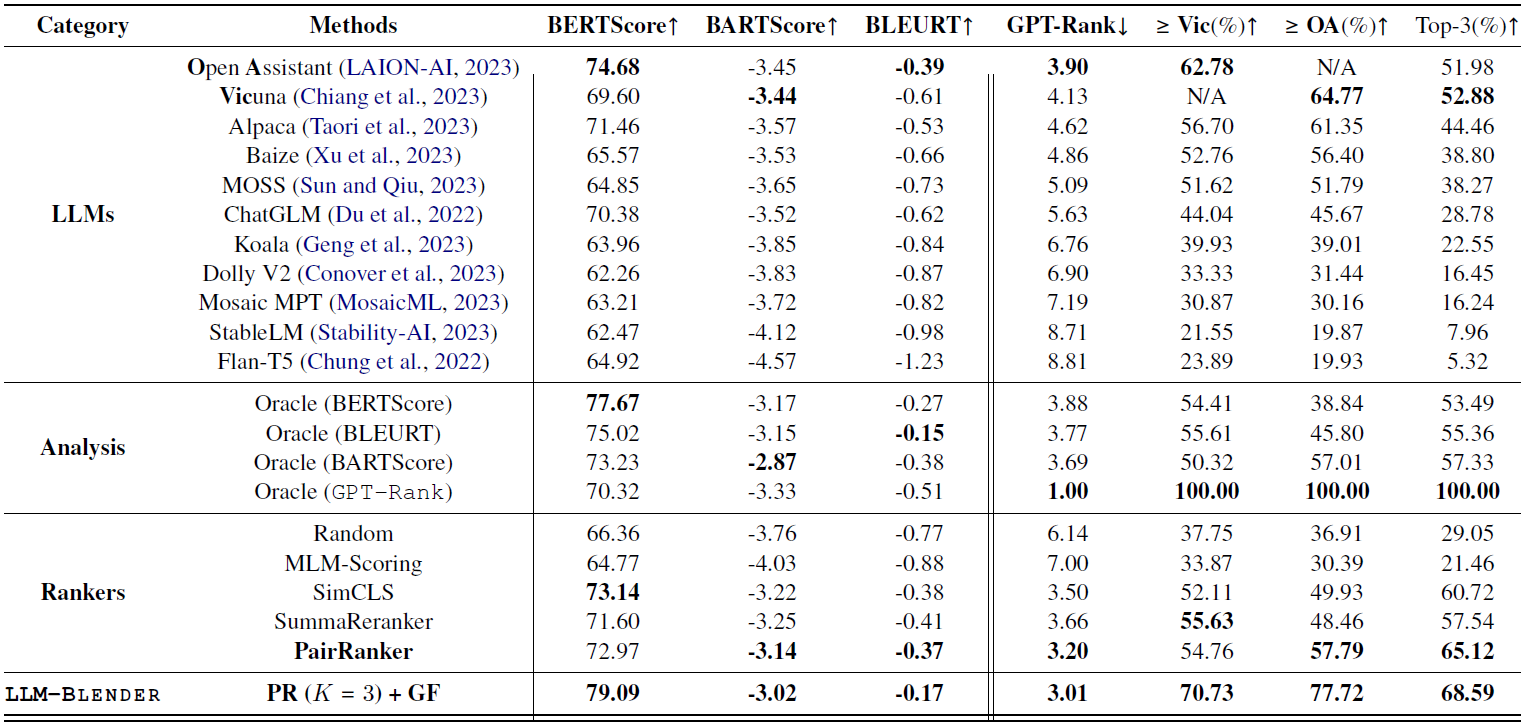
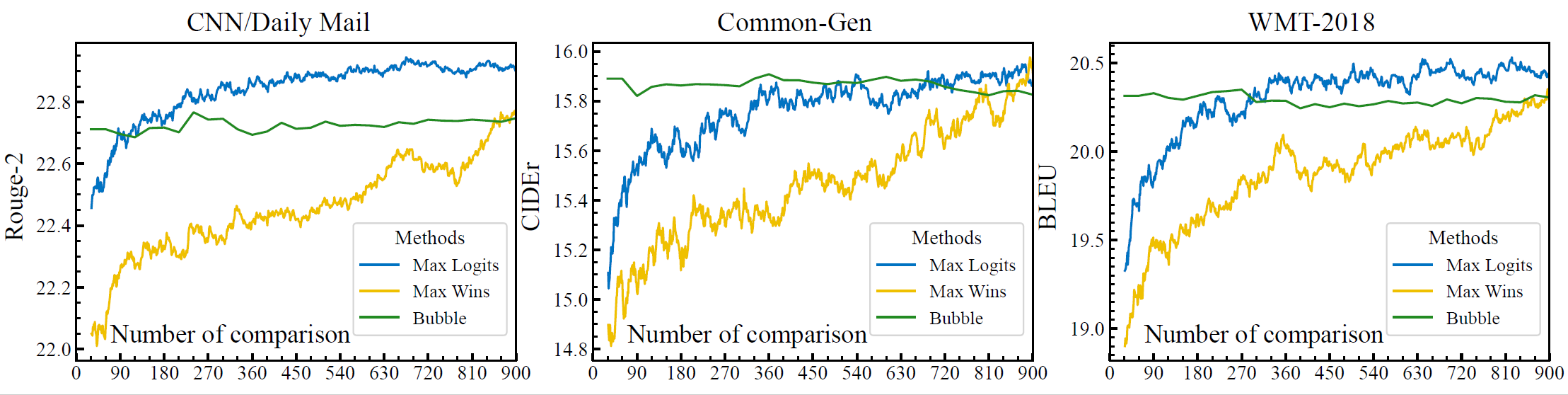
LLM-Blender: Ensembling Large Language Models with Pairwise Ranking and Generative Fusion [ACL2023]
Authors: Dongfu Jiang, Xiang Ren, Bill Yuchen Lin[AI2-Mosaic] [USC-INK]
@inproceedings{llm-blender-2023,
title = "LLM-Blender: Ensembling Large Language Models with Pairwise Comparison and Generative Fusion",
author = "Jiang, Dongfu and Ren, Xiang and Lin, Bill Yuchen",
booktitle = "Proceedings of the 61th Annual Meeting of the Association for Computational Linguistics (ACL 2023)",
year = "2023"
}